노원구 COVID-19 온톨로지 — 20분 walkthrough
covid19 예제에서 import한 9개 데이터셋 위에 엔티티(Entity)와 관계(Relationship)를 정의하고, 그래프 탐색기 · 엔티티 지도로 직접 탐색해 보는 후속편입니다. 데이터셋·파이프라인 단계에서 데이터를 표로 다뤘다면, 온톨로지 레이어에서는 같은 동·병원·환자를 노드와 간선으로 봅니다.
- covid19 예제를 끝까지 따라해 컬렉션
노원구 COVID-19 분석에 9개 데이터셋이 import된 상태 - D.Hub 계정 (covid19 예제와 동일 사용자)
시나리오와 사용 데이터셋
이 예제에서는 covid19에서 import된 9개 데이터셋 중 다음 3개를 엔티티의 backing dataset으로 씁니다.
| 데이터셋 | 엔티티 | 식별 키 | 표시 컬럼 |
|---|---|---|---|
clinics | Clinic | clinic_id | clinic_name |
patient | Patient | patient_id | patient_id |
region_dong | Region | sido·sigungu·dong (복합키) | dong |
나머지 6개 데이터셋은 여기서 직접 쓰지 않습니다 — 그중 hotspot_result는 본문 마지막 다음 단계에서 추가 모델링 아이디어로 소개합니다.
Step 1. 온톨로지 빌더 진입 (1분)
- 좌측 사이드바 온톨로지 섹션에서 모델링을 클릭해 모델링 리스트를 엽니다.
- 모델링 리스트에는 모든 컬렉션이 표시됩니다.
노원구 COVID-19 분석컬렉션 행을 클릭합니다. (Step 2~3에서 만든 컬렉션이라 엔티티 0개 상태로 이미 목록에 있습니다 — 따로 생성할 필요가 없습니다.) - 해당 컬렉션의 온톨로지 빌더 캔버스가 열립니다.
- 캔버스가 빈 상태로 보입니다(엔티티/관계가 아직 0개).
- 좌측 네비게이션 패널에 템플릿 ┃ 엔티티 뷰 토글이 있고, 기본 템플릿 뷰에
사람·조직·제품등 엔티티 템플릿이 보입니다. 엔티티 뷰로 전환하면 엔티티 추가(+) 버튼이 나타납니다. - 우측에 인스펙터(현재는 비어 있음)가 보여야 합니다.
Step 2. 엔티티 3개 정의 (5분)
세 종류의 엔티티를 만듭니다. 좌측 네비게이션 패널에서 엔티티 뷰로 전환한 뒤 엔티티 추가(+) 버튼을 누르면 엔티티 만들기 모달이 열립니다. 세부 정보 탭에서는 이름·별칭·설명을 입력하고, 속성 탭에서는 속성(필드)·타입과 식별 키·표시 컬럼을 지정합니다. 마지막으로 엔티티 만들기 버튼을 눌러 저장합니다.
엔티티 이름은 데이터셋과 같은 규칙(소문자로 시작, 소문자·숫자·밑줄만)을 따릅니다. 화면에 보이는 대문자 이름은 별칭에 넣으면 됩니다. 아래의 Clinic/Patient/Region이 별칭이고, 시스템 이름은 각각 clinic/patients/region입니다. (patients는 backing 데이터셋 patient와 헷갈리지 않도록 복수형으로 둡니다.)
2-1. Clinic
- 좌측 패널 엔티티 뷰에서 엔티티 추가(+) 버튼을 클릭해 엔티티 만들기 모달을 엽니다.
- 세부 정보 탭을 입력합니다.
- 이름:
clinic - 별칭:
Clinic - 설명: 안심병원·선별진료소
- 이름:
- 속성 탭에서 속성을 추가하고 각 행의 타입을 지정합니다.
clinic_id (Text),clinic_name (Text),clinic_type (Text),latitude (Decimal),longitude (Decimal)- 식별 키:
clinic_id - 표시 컬럼:
clinic_name
- 엔티티 만들기 버튼으로 저장합니다.
2-2. Patient
- 다시 엔티티 추가(+) → 엔티티 만들기 모달을 엽니다.
- 세부 정보 탭: 이름
patients· 별칭Patient· 설명환자 위치·감염일 - 속성 탭:
patient_id (Text),age_group (Text),sido (Text),sigungu (Text),dong (Text),infection_date (Date)- 식별 키:
patient_id· 표시 컬럼:patient_id
- 식별 키:
- 엔티티 만들기 버튼으로 저장합니다.
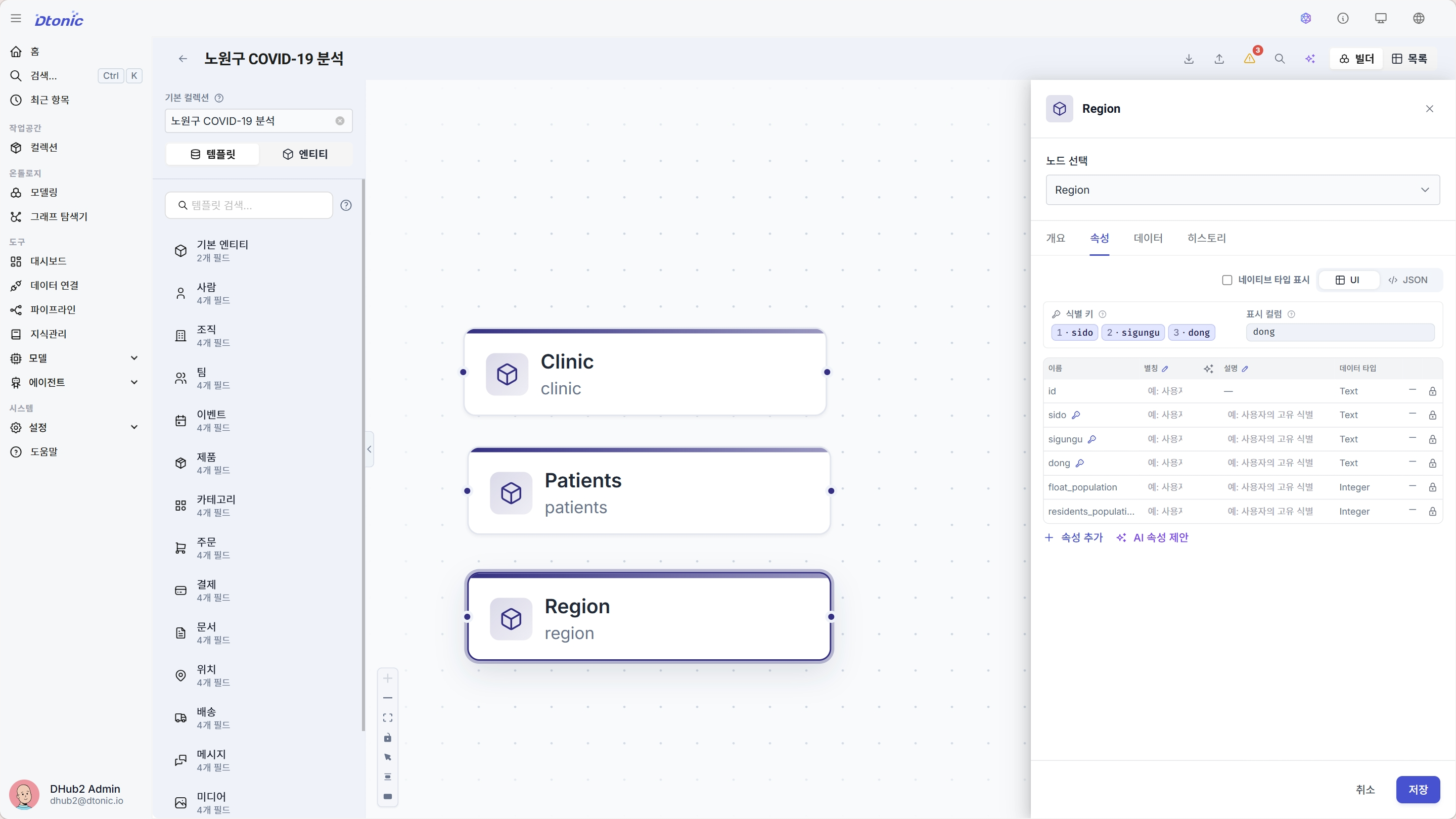
2-3. Region
- 엔티티 추가(+) → 엔티티 만들기 모달을 엽니다.
- 세부 정보 탭: 이름
region· 별칭Region· 설명동별 인구 통계 - 속성 탭:
sido (Text),sigungu (Text),dong (Text),float_population (Integer),residents_population (Integer)- 식별 키 (복합키):
sido,sigungu,dong— 세 컬럼을 모두 식별 키에 추가합니다. - 표시 컬럼:
dong
- 식별 키 (복합키):
- 엔티티 만들기 버튼으로 저장합니다.
- 캔버스에
Clinic,Patient,Region세 개의 엔티티 노드가 보입니다. - 각 노드를 클릭하면 우측 인스펙터에 속성 목록과 식별 키 / 표시 컬럼 필드가 채워져 있습니다.
Region인스펙터의 식별 키 패널에 세 개의 키 컬럼(sido·sigungu·dong)이 순서대로 나열되어 있어야 합니다.
Step 3. 관계 2개 정의 (4분)
그래프 뷰에서 엔티티 간 관계는 노드의 연결 핸들을 다른 노드로 드래그해서 만듭니다. 드래그를 놓는 순간 관계 만들기 모달이 열리고, 소스·대상 엔티티는 드래그한 방향대로 자동 지정됩니다.
3-1. Patient lives_in Region
Patient노드의 테두리에 마우스를 올려 연결 핸들(작은 점)을 표시합니다.- 핸들에서 시작해 마우스를 드래그해
Region노드 위에서 놓습니다. - 관계 만들기 모달에서 이름에
lives_in을 입력합니다.- 소스 엔티티
Patient· 대상 엔티티Region은 드래그 방향대로 자동 지정됩니다.
- 소스 엔티티
- 관계 만들기 버튼으로 저장합니다.
3-2. Clinic located_in Region
Clinic노드 핸들 →Region노드로 드래그.- 관계 만들기 모달에서 이름에
located_in을 입력합니다.- 소스 엔티티
Clinic· 대상 엔티티Region은 드래그 방향대로 자동 지정됩니다.
- 소스 엔티티
- 관계 만들기 버튼으로 저장합니다.
- 캔버스에
Patient → lives_in → Region,Clinic → located_in → Region두 개의 화살표가 그려져 있습니다. Region노드에 두 개의 화살표가 모입니다.- 관계 화살표를 클릭하면 인스펙터에 관계 타입과 방향이 표시됩니다.
Step 4. 파이프라인으로 엔티티에 데이터 적재 (8분)
엔티티는 스키마(형태) 만 정의하고, 실제 인스턴스는 데이터셋의 행을 파이프라인으로 흘려보내 채웁니다. 코드 노드의 출력 핸들을 엔티티 노드에 연결하면 그 출력이 해당 엔티티로 지정되고, Step 2에서 설정한 식별 키를 기준으로 행이 그래프에 병합(upsert)됩니다. (온톨로지 빌더 인스펙터의 데이터 탭은 적재된 행을 보여주는 읽기 전용 미리보기이며, 매핑은 파이프라인에서 합니다.)
세 엔티티를 하나의 파이프라인 안에서 각각 데이터셋 → SQL 코드 노드 → 엔티티 노드 체인으로 적재하겠습니다.
4-1. Clinic ← clinics 데이터셋
-
컬렉션 상세에서 항목 추가 → 파이프라인으로 워크플로우 편집기를 엽니다.
-
컴포넌트 라이브러리의 컬렉션 섹션에서
clinics데이터셋을 캔버스로 드래그합니다. -
빠른 추가 → 코드에서 SQL 노드를 추가하고,
clinics노드의 출력 핸들을 SQL 노드 입력에 연결합니다. -
SQL 노드 코드 탭에 엔티티 속성과 같은 이름의 컬럼을 선택하는 쿼리를 작성합니다.
SELECT clinic_id, clinic_name, clinic_type, latitude, longitude
FROM clinics -
빠른 추가 → 온톨로지에서 엔티티 노드를 캔버스로 드래그하면 엔티티 소스 추가 선택기가 열립니다. 여기서
Clinic엔티티를 선택합니다. -
SQL 노드의 출력 핸들을 방금 추가한
Clinic엔티티 노드에 연결합니다. 연결되면 코드 노드의 출력이 자동으로 소스 유형 = 엔티티(대상Clinic)로 설정되고, 엔티티 출력의 쓰기 모드는 기본값이 병합(upsert)입니다. -
SQL 노드 옵션 탭 → 출력에서 소스 유형이 엔티티, 쓰기 모드가 병합인지 확인합니다. (다른 값이면 이 탭에서 조정합니다.)
출력 엔티티에 식별 키가 없으면 옵션 탭 출력에 Identity Keys 필요 경고가 표시됩니다. Ontology Builder에서 열기로 이동해 식별 키를 먼저 지정하세요. (Step 2에서 지정했다면 경고가 없습니다.)
4-2. Patient ← patient 데이터셋
patient 데이터셋 → SQL 노드 체인을 같은 방식으로 추가하고, 엔티티 노드로 Patient를 골라 SQL 노드 출력에 연결합니다.
SELECT patient_id, age_group, sido, sigungu, dong, infection_date
FROM patient
- 출력: 연결 시 소스 유형 엔티티, 대상
Patient, 쓰기 모드 병합으로 자동 설정됩니다.
4-3. Region ← region_dong 데이터셋
region_dong 데이터셋 → SQL 노드 체인을 추가하고, 엔티티 노드로 Region을 골라 SQL 노드 출력에 연결합니다.
SELECT sido, sigungu, dong, float_population, residents_population
FROM region_dong
- 출력: 연결 시 소스 유형 엔티티, 대상
Region, 쓰기 모드 병합으로 자동 설정됩니다. Region은 복합 식별 키(sido·sigungu·dong)이므로 세 컬럼이 모두 SELECT에 포함돼야 병합이 동작합니다.
4-4. 저장 · 실행
- 우상단 저장으로 파이프라인 이름(예:
온톨로지 적재)을 지정해 저장합니다. - 지금 실행을 클릭합니다. 세 코드 노드가 실행되어 각 엔티티 테이블에 행이 기록되고 그래프 데이터베이스로 전파됩니다.
- 파이프라인 캔버스에
데이터셋 → SQL → 엔티티체인 3개가 보입니다. - 실행 배치 상태가
성공이 되면 각 엔티티에 행이 적재된 것입니다. - 적재가 끝나면 다음 Step의 그래프 탐색기에 노드가 보이기 시작합니다 — 데이터 양에 따라 몇 초~수십 초 걸릴 수 있습니다.
Step 5. 그래프 탐색기로 탐색 (3분)
빌더에서 정의한 엔티티/관계가 실제 그래프에 올라갔는지 눈으로 확인합니다.
-
사이드바에서 온톨로지 → 그래프 탐색기를 엽니다.
-
좌측 메타데이터 패널의 엔티티 항목에
clinic,patients,region이 보이고 각 옆에 노드 개수가 표시됩니다. (그래프 라벨은 엔티티의 시스템 이름(소문자)입니다 — 별칭Clinic이 아니라clinic.) -
patients라벨을 클릭하면 자동으로MATCH (n:patients) RETURN n쿼리가 실행되어 환자 노드들이 시각화 영역에 펼쳐집니다. -
환자 노드 하나를 더블 클릭하면 연결된
region노드가 추가로 펼쳐집니다(lives_in관계 활용). -
(선택) 하단 쿼리 콘솔에 다음 Cypher를 입력하고 실행을 클릭하면 환자-거주지 관계를 한 번에 시각화합니다.
MATCH (p:patients)-[:lives_in]->(r:region)
RETURN p, r
LIMIT 50
- 메타데이터 패널의 엔티티 카운트가
clinic 20,patients 13,region 9근사값으로 채워져 있어야 합니다. - 카운트가 0이면 Step 4의 데이터 매핑이 아직 적재되지 않은 상태입니다 — 30초~1분 기다린 뒤 페이지 새로고침.
- Cypher 쿼리 결과의 노드 색상은 라벨별로 자동 지정됩니다.
Step 6. 엔티티 지도로 안심병원 분포 시각화 (2분)
Clinic 엔티티는 latitude/longitude 속성이 있어 지도 위에 바로 표시할 수 있습니다.
- 사이드바에서 온톨로지 → 모델링 리스트에서
Clinic엔티티 항목을 선택합니다. - 엔티티 상세에서 지도 탭을 클릭합니다 (URL은
/ontology/entities/<clinic-id>/map형태). - Clinic의
latitude/longitude속성이 자동 인식되어 노원구 영역에 20개의 마커가 표시됩니다. - 마커 하나를 클릭하면
clinic_name,clinic_type,sample_available등 속성이 팝업으로 표시됩니다.
- 지도 위에 노원구 영역의 20개 안심병원·선별진료소 마커가 보입니다.
Patient엔티티에는latitude/longitude속성이 없어 지도에 직접 표시되지 않습니다. 환자 위치를 지도에 보고 싶다면 본문 다음 단계 표의 hotspot_result 활용 아이디어를 참고하세요.
마치며
수고하셨습니다. 이제 covid19 데이터셋 위에 의미 레이어를 얹어 그래프로 다룰 수 있습니다. 20분 동안 만든 결과물을 정리하면 다음과 같습니다.
- ✅ 엔티티 3개 (
Clinic,Patient,Region) + 식별 키 / 표시 컬럼 설정 - ✅ 관계 2개 (
lives_in,located_in) - ✅ 데이터셋 매핑 3건 (clinics / patient / region_dong) → 자동 sink로 그래프 데이터베이스 적재
- ✅ 그래프 탐색기 시각 탐색 + Cypher 쿼리 1건
- ✅ Clinic 분포 지도 시각화
다음 단계
| 더 깊이 가려면 | 가이드 |
|---|---|
hotspot_result로 환자 접촉 관계(자기참조) 모델링 | 관계 (Relationships) |
| Cypher로 직접 그래프 질의 작성 | Cypher 가이드 |
| 스키마를 JSON 또는 CSV로 일괄 정의 | 스키마 편집기 |
| 같은 흐름을 API/cURL로 자동화 | 개발자 가이드 - API 튜토리얼 |
| 컬렉션·온톨로지를 다른 사용자에게 공유 | 공유 및 권한 |
| 데이터셋·파이프라인 단계로 돌아가기 | covid19 예제 |
문제 해결
| 증상 | 점검 |
|---|---|
| Step 2에서 속성 타입이 자동으로 추론되지 않음 | 인스펙터에서 각 속성을 클릭해 타입을 직접 지정 (Text / Integer / Decimal / Numeric / Boolean / Date) |
| Step 3에서 드래그 시 관계 만들기 대화상자가 안 뜸 | 시작 핸들이 정확히 노드 테두리의 점에서 출발했는지 확인. 노드 내부에서 시작하면 노드 이동으로 인식됨 |
| Step 4 데이터 탭에서 데이터셋 목록이 비어 있음 | 컬렉션 범위가 일치하는지 확인 (동일 컬렉션의 데이터셋만 노출). 노원구 COVID-19 분석 컬렉션을 선택했는지 점검 |
| Step 5 그래프 탐색기 라벨 카운트가 0 | Step 4 데이터 저장 직후 sink 작업이 진행 중. 30초~1분 기다린 뒤 페이지 새로고침. 그래도 0이면 식별 키 매핑 누락 여부 점검 |
| Step 6 지도에 마커가 보이지 않음 | Clinic의 latitude/longitude가 Decimal로 매핑되었는지 확인. 문자열(Text)로 매핑되면 좌표로 인식되지 않음. 좌표계는 WGS84 가정 |