노원구 COVID-19 분석 — 25분 walkthrough
서울 노원구의 안심병원 위치, 동별 인구, 환자 이동 동선 데이터를 D.Hub에 올려 컬렉션 → 데이터셋 → 파이프라인 → 대시보드를 한 번에 완성하는 예제입니다. CSV 9개(총 12.5 KB)와 D.Hub 계정만 있으면 따라 할 수 있습니다.
- D.Hub 계정 (관리자에게 발급받은 사용자명·비밀번호 또는 SSO)
- 웹 브라우저(데스크톱 권장)
- CSV 9개를 받아 압축 해제할 폴더 (다음 단계에서 다운로드)
시나리오와 데이터
2020년 서울 노원구의 COVID-19 hotspot 분석 시나리오를 재구성한 예제입니다. 9개 파일은 크게 네 가지 역할로 나뉩니다.
| 분류 | 파일 | 행수 | 역할 |
|---|---|---|---|
| 차원·필터 | sido_filter.csv · sigungu_filter.csv | 3 · 6 | 시도·시군구 후보 목록 |
| 마스터 | clinics.csv | 20 | 안심병원·선별진료소 (위·경도 포함) |
| 인구 | residents_population.csv · floating_population.csv | 9 · 9 | 동별 주민 인구, 유동 인구 |
| 인구 (조인본) | region_dong.csv · region_dong_info.csv | 33 · 8 | 인구 조인 결과 + 필터 변형 |
| 팩트 | patient.csv · hotspot_result.csv | 13 · 23 | 환자 위치·감염일, 접촉 hotspot |
walkthrough에서 본격적으로 쓰는 데이터는 clinics(Step 6 지도), patient(Step 7 라인 차트), residents_population + floating_population(Step 4 조인) 세 그룹입니다. 나머지 CSV 6개는 데이터셋으로만 import 해 두고, 본격 분석은 마지막 다음 단계에서 안내합니다.
데이터 다운로드
| 받기 | 크기 | 비고 |
|---|---|---|
| 한 번에 받기 (covid19.zip) | ~10 KB | Step 1에서 사용 |
| clinics.csv | 3.6 KB | 안심병원·선별진료소 (lat/long) |
| patient.csv | 0.9 KB | 환자 위치·감염일 |
| hotspot_result.csv | 4.9 KB | 환자 접촉 hotspot (POINT geom) |
| residents_population.csv | 0.4 KB | 동별 주민 인구 |
| floating_population.csv | 0.4 KB | 동별 유동 인구 |
| region_dong.csv | 1.6 KB | 인구 조인본 |
| region_dong_info.csv | 0.4 KB | 인구 조인본 필터 변형 |
| sido_filter.csv | 0.05 KB | 시도 필터 후보 |
| sigungu_filter.csv | 0.2 KB | 시군구 필터 후보 |
Step 1. 자산 받기 · D.Hub 로그인 (2분)
- 위 표의 한 번에 받기 (covid19.zip) 링크를 클릭해 zip을 내려받습니다.
- zip을 임의의 폴더에 압축 해제합니다. CSV 파일 9개가 평탄하게(
covid19/하위 폴더 없이) 풀려야 합니다. - 브라우저에서 D.Hub 포털 URL에 접속합니다.
- 사용자명·비밀번호를 입력하고 로그인을 클릭합니다. SSO 환경이면 SSO 로그인 버튼으로 진행합니다.
- 로컬 폴더에 CSV 파일 9개가 평탄하게 풀려 있습니다.
- 브라우저가 D.Hub 홈 화면(
/home)에 도착해 있습니다.
Step 2. 컬렉션 노원구 COVID-19 분석 생성 (1분)
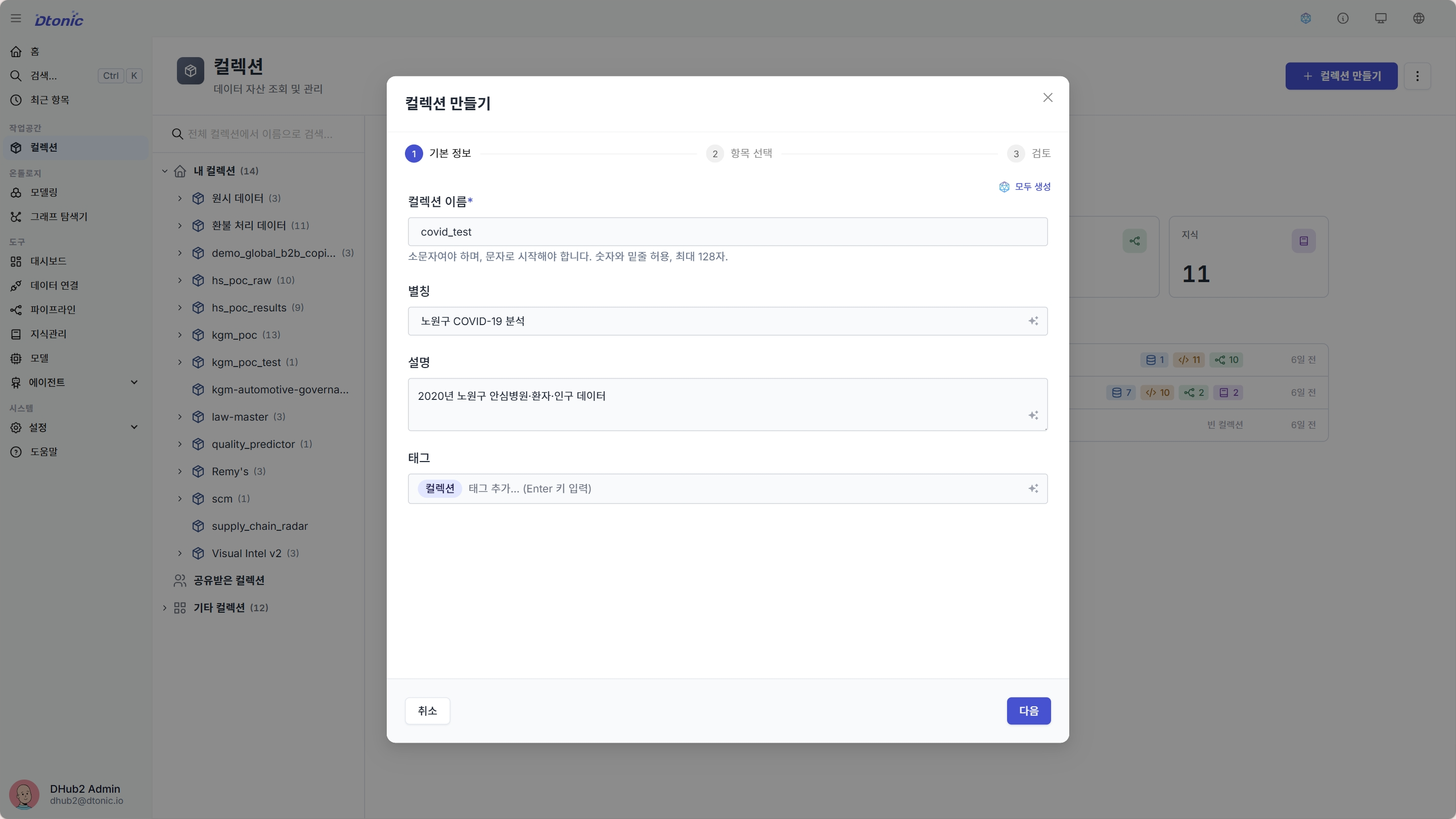
- 좌측 사이드바에서 컬렉션으로 이동한 뒤 컬렉션 만들기를 클릭하면 생성 마법사가 열립니다.
- 기본 정보 단계에서 컬렉션 이름에
covid_test를, 별칭으로노원구 COVID-19 분석을 입력합니다. - 설명 칸에
2020년 노원구 안심병원·환자·인구 데이터를 입력합니다(선택). - 다음으로 항목 선택·검토 단계를 지난 뒤 마지막 단계에서 컬렉션 만들기를 클릭합니다.
- 좌측 사이드바 컬렉션 아래에
노원구 COVID-19 분석컬렉션이 보입니다. - 페이지가 자동으로 컬렉션 상세로 이동했습니다 (URL에 컬렉션 ID 포함).
Step 3. 9개 CSV 빠른 추가 업로드 (3분)
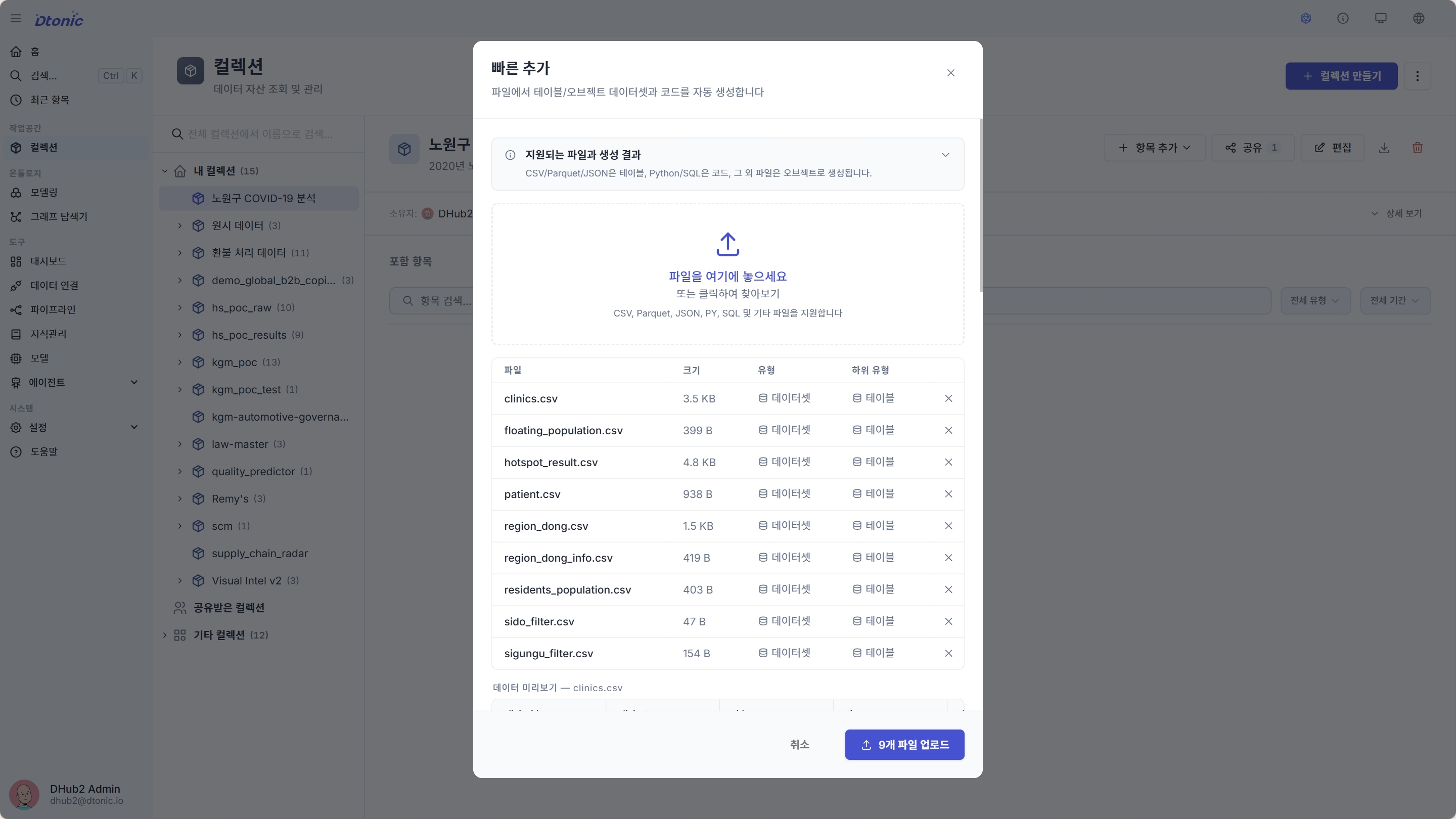
- 컬렉션 상세 페이지 헤더에서 항목 추가 → 빠른 추가… 메뉴를 선택합니다.
- 업로드 다이얼로그에 Step 1에서 압축 해제한 CSV 파일 9개를 모두 드래그 앤 드롭 하거나, 파일 선택 다이얼로그에서 멀티 선택합니다.
- 9개 항목이 모두 목록에 보이는지 확인한 뒤 업로드 버튼을 클릭합니다.
- 업로드가 끝나면 데이터셋 목록에 새 항목 9개가 자동 생성됩니다.
- 컬렉션의 포함 항목 목록에 다음 9개 데이터셋이 보입니다:
clinics,floating_population,hotspot_result,patient,region_dong,region_dong_info,residents_population,sido_filter,sigungu_filter. - 각 데이터셋의 행수가 위 §시나리오와 데이터 표의 값과 일치해야 합니다 (
clinics20행,patient13행 등). - 행수가 맞지 않으면 CSV 인코딩(UTF-8)이나 헤더 라인을 다시 확인하세요.
Step 4. 인구 조인 파이프라인 만들기 (7분)
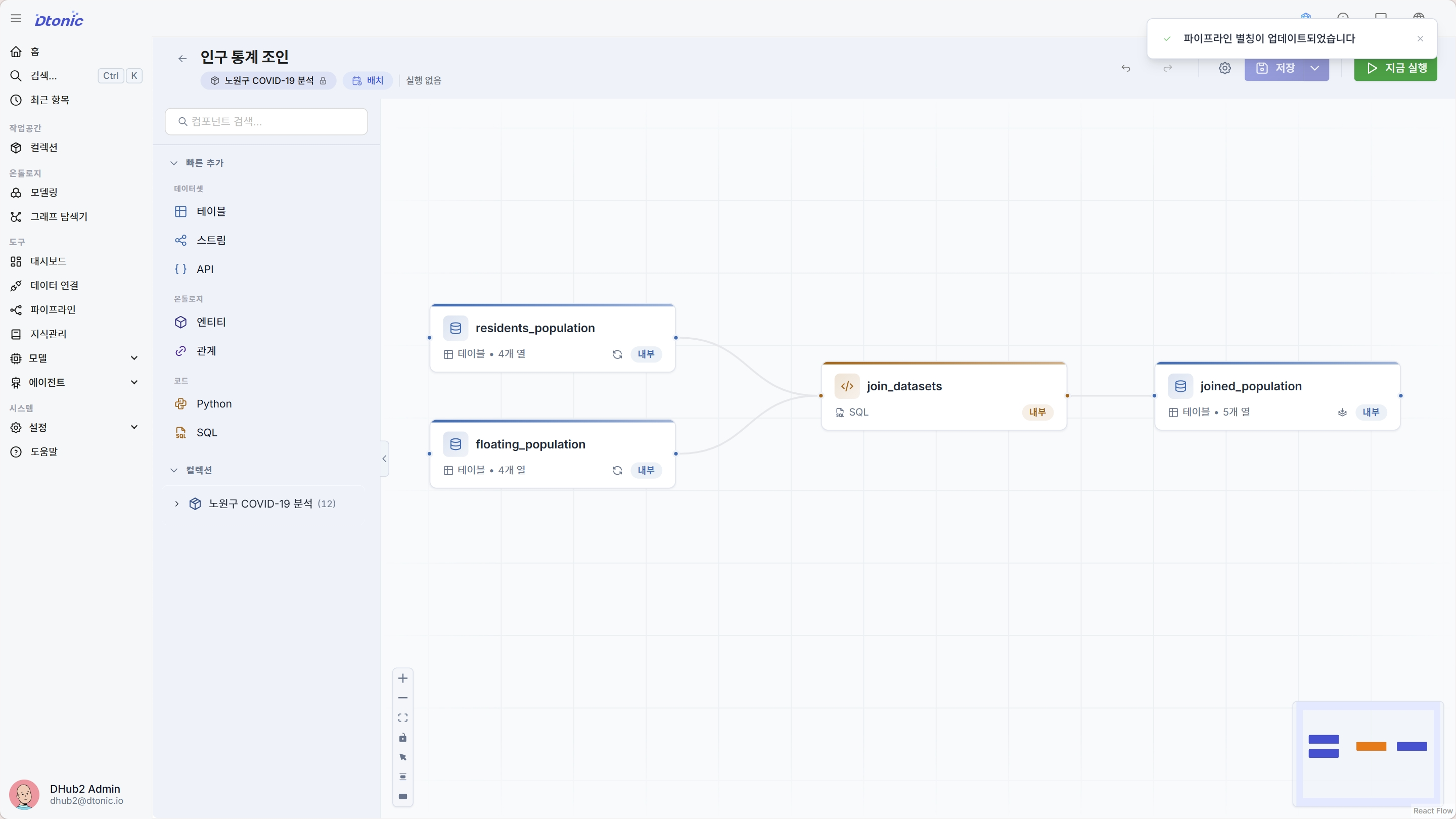
residents_population(동별 주민 수)과 floating_population(동별 유동 인구 수)을 동(sido·sigungu·dong) 키로 조인해 동별 종합 인구 통계를 만듭니다. D.Hub 파이프라인에는 전용 조인 노드가 없어 조인·집계 같은 변환은 SQL(또는 Python) 코드 노드 안에서 처리합니다. 구조는 소스 데이터셋 노드 → 코드 노드 → 출력 데이터셋 노드 순으로 구성합니다.
-
컬렉션 상세에서 항목 추가 → 파이프라인을 선택하면 워크플로우 편집기가 바로 열립니다. (파이프라인 이름은 마지막 저장 단계에서 지정합니다.)
-
좌측 컴포넌트 라이브러리의 컬렉션 섹션에서
residents_population과floating_population데이터셋을 캔버스로 각각 드래그합니다(소스 데이터셋 2개). 이미 컬렉션에 import한 데이터셋을 그대로 재사용하는 방식입니다. -
컴포넌트 라이브러리의 빠른 추가 → 코드에서 SQL 노드를 캔버스에 추가합니다.
-
두 데이터셋 노드의 오른쪽(출력) 핸들을 SQL 코드 노드의 왼쪽(입력) 핸들에 각각 연결합니다. 연결한 데이터셋은 코드 안에서 데이터셋 이름과 같은 테이블로 참조됩니다.
-
SQL 코드 노드를 선택하고 코드 탭에서 다음 조인 쿼리를 작성합니다.
SELECT
r.sido, r.sigungu, r.dong,
r.residents_population,
f.float_population
FROM residents_population AS r
INNER JOIN floating_population AS f
ON r.sido = f.sido
AND r.sigungu = f.sigungu
AND r.dong = f.dong입력 테이블 이름연결한 입력 테이블 이름은 코드 노드의 옵션 탭에서 확인합니다(기본값은 데이터셋 이름). 쿼리의
FROM/JOIN대상이 이 이름과 일치해야 합니다. -
SQL 코드 노드를 우클릭하고 결과 데이터셋 추가를 선택하면 출력 데이터셋 노드가 자동으로 생성·연결됩니다. 생성된 출력 데이터셋의 이름을
joined_population으로 지정합니다. -
우상단 저장을 클릭하고 파이프라인 이름에
인구 통계 조인을 입력해 저장합니다.
- 워크플로우 편집기 캔버스에 노드 4개(데이터셋 소스 2 + SQL 코드 + 출력 데이터셋)가 연결된 그래프가 보입니다.
- 파이프라인 목록으로 돌아가면
인구 통계 조인항목이 보입니다. - 아직 실행하지는 않았습니다 — 다음 step에서 실행합니다.
Step 5. 파이프라인 실행 · 배치 결과 확인 (2분)
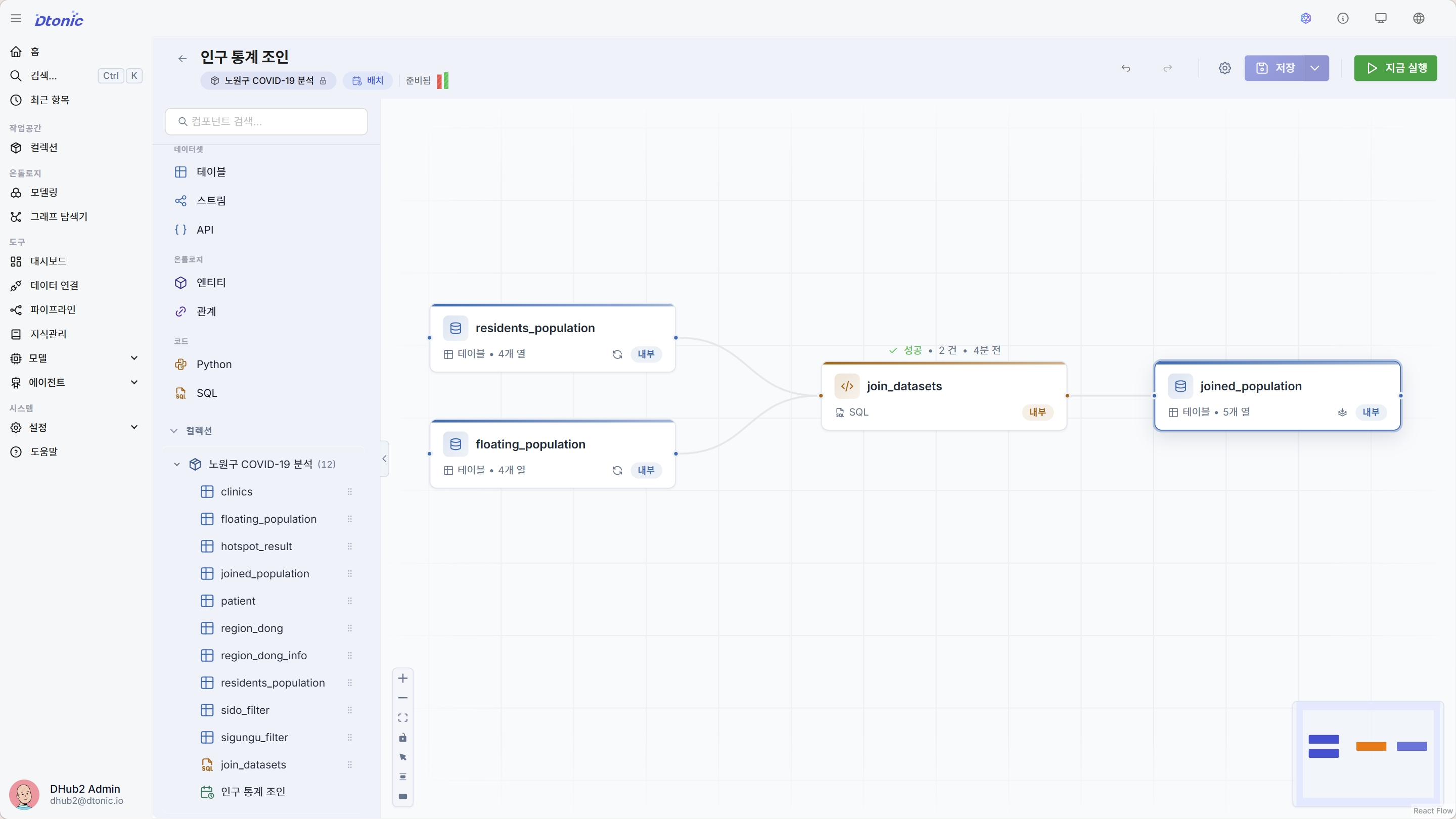
- 워크플로우 편집기 상단의 지금 실행 버튼을 클릭합니다.
- 우측에 새 배치가 생성되며 상태가
실행 중→성공으로 바뀝니다. - 배치 카드를 클릭하면 실행 트레이스(각 노드의 처리 행수, 소요 시간)를 볼 수 있습니다.
- 좌측 컬렉션의 데이터셋 목록을 새로고침하면
joined_population이 새로 생성되어 있습니다.
- 배치 상태가
성공(녹색)이어야 합니다. - 새 데이터셋
joined_population의 행수는 11개(양쪽 공통 동 수)이며 컬럼은sido,sigungu,dong,residents_population,float_population5개입니다. - 실패(빨강) 상태라면 트레이스에서 어느 노드가 어떤 오류로 실패했는지 확인합니다 (디버깅 가이드).
Step 6. 대시보드 + 안심병원 지도 위젯 (4분)
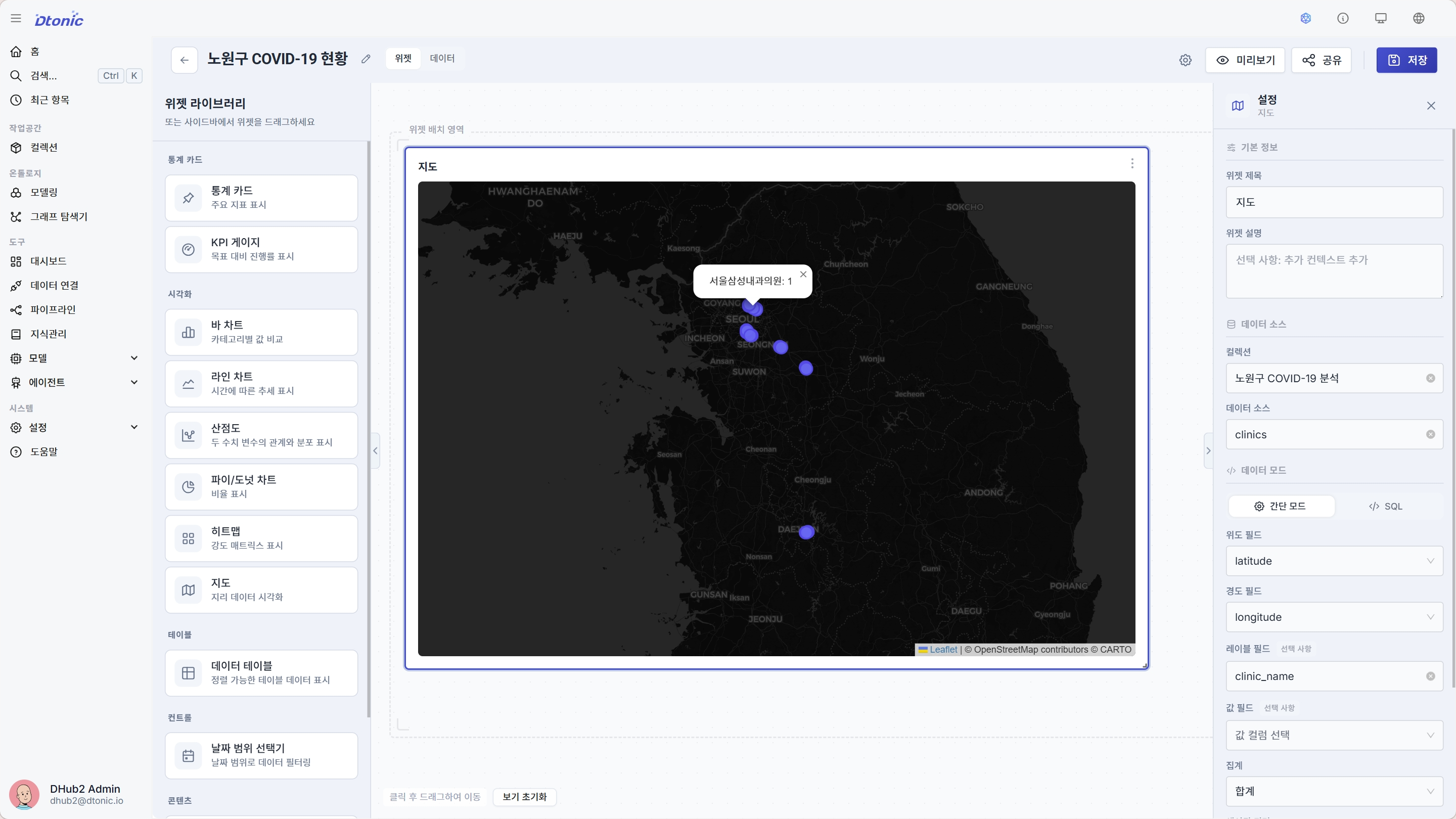
clinics 데이터셋의 위·경도 컬럼을 지도 위젯에 매핑합니다.
- 좌측 사이드바에서 대시보드를 클릭한 뒤 대시보드 만들기 버튼을 누르면 편집 화면(빌더)이 바로 열립니다.
- 편집 화면 상단의 제목을 클릭해 대시보드 이름
노원구 COVID-19 현황을 입력합니다. - 좌측 위젯 라이브러리 열기 → 시각화 → 지도(Map) 위젯을 캔버스로 드래그합니다.
- 위젯이 선택된 상태에서 우측 구성 패널의 데이터 소스 섹션에서 데이터를 연결합니다. 새로 추가한 위젯은 컬렉션을 먼저 선택해야 데이터셋 목록이 활성화됩니다.
- 컬렉션:
노원구 COVID-19 분석선택 — 고르기 전에는 데이터셋 칸에 먼저 컬렉션을 선택하세요 가 표시됩니다. - 데이터 소스:
clinics선택
- 컬렉션:
- 데이터셋을 선택하면 그 아래에 데이터 모드 섹션이 나타납니다. 간단 모드를 선택하면 같은 섹션에 위치 필드 입력칸이 표시됩니다.
- 위도 필드:
latitude - 경도 필드:
longitude - 레이블 필드:
clinic_name— 마커 팝업에 표시될 이름
- 위도 필드:
- 변경 적용을 클릭하면 지도가 노원구 좌표 주변으로 자동 줌인됩니다.
- 대시보드 캔버스 위에 노원구 영역을 보여주는 지도와 마커 20개(병원·선별진료소)가 보입니다.
- 마커를 클릭하면 레이블 필드로 지정한
clinic_name(안심병원 이름)이 팝업으로 떠야 합니다.
Step 7. 환자 일자별 누적 추이 라인 차트 (3분)
patient 데이터셋의 infection_date를 X축, 누적 감염자 수를 Y축으로 두는 라인 차트를 추가합니다.
- 빌더에서 위젯 라이브러리 열기 → 시각화 → 라인 차트를 캔버스로 드래그해 지도 옆에 배치합니다.
- 위젯의 구성 패널 데이터 소스 섹션에서 컬렉션
노원구 COVID-19 분석→ 데이터 소스patient를 선택합니다 (Step 6과 마찬가지로 컬렉션을 먼저 골라야 데이터셋이 활성화됩니다). - 데이터셋을 선택하면 나타나는 데이터 모드 섹션에서 SQL을 선택합니다 (간단 모드로도 되지만, 누적 합산이 필요해 SQL이 더 명료합니다).
-
쿼리 영역에 다음을 입력합니다.
SELECT
infection_date,
COUNT(*) AS daily_count,
SUM(COUNT(*)) OVER (ORDER BY infection_date) AS cumulative_count
FROM patient
GROUP BY infection_date
ORDER BY infection_date -
쿼리를 적용한 뒤 아래 컬럼 매핑 섹션에서 X축:
infection_date, Y축:cumulative_count를 지정합니다.
-
- 변경 적용 → 차트가 렌더링되면 우상단 저장으로 대시보드를 저장합니다.
- 대시보드에 지도와 라인 차트 두 위젯이 나란히 보입니다.
- 라인 차트는 2020년 8월–10월 구간의 누적 감염자 추이를 단조 증가 곡선으로 그립니다.
- 대시보드 목록(
/dashboard)에노원구 COVID-19 현황항목이 보여야 합니다.
Step 8. 마무리 · 다음 단계 (3분)
축하합니다 — D.Hub의 Collection → Dataset → Pipeline → Dashboard canonical flow를 모두 한 번씩 직접 거쳤습니다. 25분 안에 끝낸 작업을 정리하면 다음과 같습니다.
- ✅ 컬렉션 1개 (
노원구 COVID-19 분석) - ✅ 데이터셋 9개 (빠른 추가) + 1개 (파이프라인 산출물
region_population_joined) - ✅ 파이프라인 1개 (
인구 통계 조인) · 배치 1회 실행 - ✅ 대시보드 1개 + 위젯 2개 (지도 · 라인 차트)
다음 단계
| 더 깊이 가려면 | 가이드 |
|---|---|
환자 동선 hotspot 시각화 (hotspot_result 의 POINT geom) | 지도 데이터 설정 |
patient ↔ clinics ↔ region_dong 을 온톨로지로 모델링 | covid19 온톨로지 튜토리얼 |
| 같은 흐름을 API/cURL로 자동화 | 개발자 가이드 - API 튜토리얼 |
| 컬렉션을 다른 사용자/그룹에 공유 | 공유 및 권한 |
| 파이프라인을 정기 실행하도록 스케줄 | 스케줄링 |
문제 해결
| 증상 | 점검 |
|---|---|
| 빠른 추가 시 데이터셋 행수가 표와 다름 | CSV 인코딩이 UTF-8인지, 헤더 라인이 첫 줄에 있는지 확인 |
| Step 4의 조인 결과 행수가 0 | 두 소스의 sido/sigungu/dong 문자열이 정확히 일치하는지 확인 (공백·전각·반각 주의) |
Step 5의 배치 상태가 실패 | 배치 트레이스에서 실패 노드의 오류 메시지를 확인 (디버깅 가이드) |
| Step 6의 지도가 빈 화면 | clinics 데이터셋의 latitude/longitude 컬럼 타입이 숫자인지 확인 (문자열이면 데이터셋 스키마를 수정) |
| Step 7의 라인 차트가 비어 있음 | SQL 모드에서 데이터셋 이름이 정확한지 (예제 데이터셋명 patient) 확인 |