파일 업로드
파일 업로드는 PDF, DOCX 등 다양한 형식의 문서 파일을 Knowledge에 인덱싱하는 기능입니다. 업로드된 문서는 자동으로 파싱, 청킹, 임베딩 과정을 거쳐 검색 가능한 지식 데이터로 변환됩니다.
지원 파일 형식
| 형식 | 확장자 |
|---|---|
.pdf | |
| Word | .docx, .doc |
| PowerPoint | .pptx |
| Excel | .xlsx |
| CSV | .csv |
| HTML | .html |
| 텍스트 | .txt |
| 마크다운 | .md |
지원되지 않는 확장자의 파일은 선택 시 자동으로 걸러집니다.
업로드 화면
파일 업로드 화면은 /knowledge/:knowledgeId/documents/files/upload 경로에서 접근할 수 있습니다. Knowledge 상세 페이지의 문서 (Documents) 탭에서 새 문서 추가 → 파일 업로드를 선택하여 진입합니다.
업로드는 3단계 위저드로 구성되어 있습니다:
| 단계 | 이름 | 설명 |
|---|---|---|
| Step 1 | 파일 업로드 (Upload Files) | 파일 선택 및 파싱 옵션 설정 |
| Step 2 | 청킹 설정 (Chunk Settings) | 청킹 전략 및 파라미터 설정 |
| Step 3 | 검토 및 제출 (Review & Submit) | 인덱싱 옵션 확인 및 최종 제출 |
Step 1: 파일 선택 + 파일별 메타데이터
드래그 앤 드롭 영역에 파일을 끌어다 놓거나 클릭하여 파일을 선택합니다.
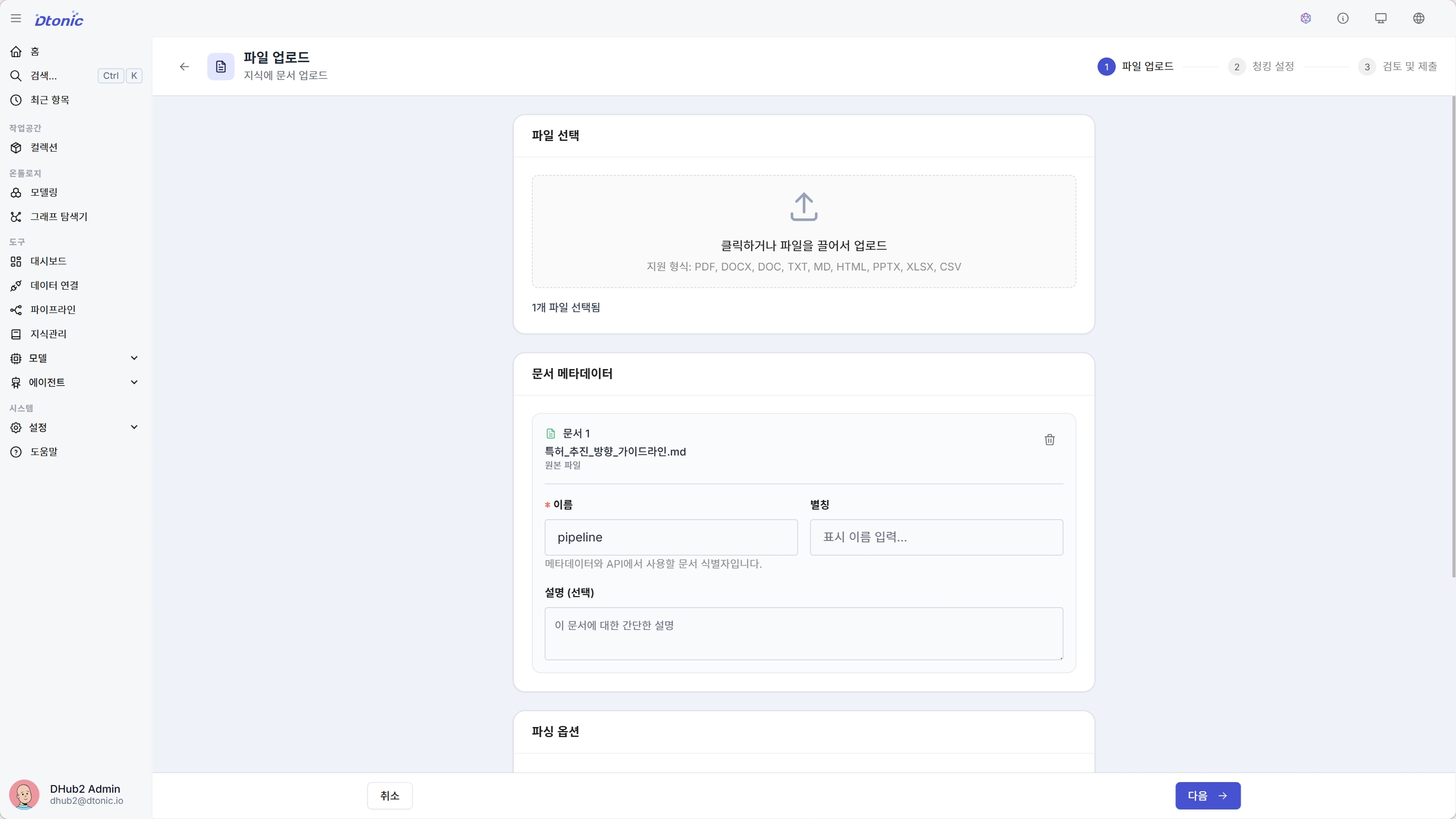
- 다중 파일 업로드: 여러 파일을 동시에 선택하거나 드래그하여 추가할 수 있습니다
- 파일 제거: 추가된 파일 목록에서 개별 파일을 제거할 수 있습니다
- 형식 필터링: 지원되지 않는 형식의 파일은 자동으로 필터링됩니다
- 파일별 메타데이터: 각 파일 행에서 제목(이름, 필수), 별칭, 설명을 인라인으로 입력할 수 있습니다. 메타데이터는 인덱싱 후에도 문서 행에 유지됩니다.
이 단계에서는 파일별 메타데이터와 함께 공용 파싱 옵션을 설정합니다.
단계 간 옵션 보존
위저드 Step 1 → Step 2 → Step 3 사이에서 모든 입력 값(파싱 옵션·청킹 옵션·파일별 메타데이터)은 유지됩니다. 이전 단계로 돌아갔다가 다시 진행해도 입력한 값이 사라지지 않으므로, 청킹 전략을 비교하거나 옵션을 미세 조정하기 편합니다.
처리 옵션
파싱 옵션 (Step 1)
파싱 옵션은 문서에서 텍스트를 추출하는 방법을 제어합니다.
| 옵션 | 설명 | 기본값 | 비고 |
|---|---|---|---|
| 테이블 구조 파싱 | 문서 내 테이블을 구조화하여 추출 | 활성화 | Switch on/off |
| 테이블 모드 | 테이블 추출 정확도 설정 | 빠름 (FAST) | 빠름 (FAST) 또는 정확 (ACCURATE) |
| OCR 활성화 | 이미지 내 텍스트 인식 활성화 | 비활성화 | Switch on/off |
| OCR 엔진 | 사용할 OCR 엔진 선택 | 자동 (AUTO) | 아래 표 참조 |
| 타임아웃 (초) | 파싱 최대 대기 시간 (초) | 90 | 최소 10 ~ 최대 600 |
OCR 엔진 옵션
| 엔진 | 설명 |
|---|---|
| 자동 (AUTO) | 시스템이 자동으로 최적 엔진 선택 |
| Tesseract | Google Tesseract OCR |
| EasyOCR | EasyOCR (다국어 지원) |
| RapidOCR | RapidOCR (경량 고속 엔진) |
청킹 옵션 (Step 2)
청킹 옵션은 추출된 텍스트를 검색 단위인 청크로 분할하는 방법을 결정합니다.
| 옵션 | 설명 | 기본값 | 범위 |
|---|---|---|---|
| 청킹 전략 | 텍스트 분할 알고리즘 | 하이브리드 (hybrid) | 아래 표 참조 |
| 최대 청크 길이 | 청크당 최대 토큰 수 | 500 | 100 ~ 4,000 |
| 오버랩 길이 | 인접 청크 간 겹치는 토큰 수 | 50 | 0 ~ 500 |
청킹 전략
| 전략 | 설명 | 권장 용도 |
|---|---|---|
| 하이브리드 (Hybrid) | 구조 + 크기 기반 혼합 분할 | 범용 (기본값, 권장) |
| 마크다운 (Markdown) | 마크다운 헤딩 기준 분할 | .md 파일, 구조화된 문서 |
| 계층적 (Hierarchical) | 문서 계층 구조 기반 분할 | 섹션이 명확한 긴 문서 |
| 고정 크기 (Fixed) | 고정 크기로 균일 분할 | 구조 없는 텍스트 |
| 상위-하위 (Parent-Child) | 부모-자식 관계로 계층 분할 | 상세 검색이 필요한 문서 |
이 외에도 문장 (Sentence), 시맨틱 (Semantic), 에이전틱 (Agentic) 전략을 제공합니다(총 8종). 각 전략의 상세 옵션은 청킹 및 옵션 문서를 참고하세요.
Step 2의 Chunk Preview 패널에서 현재 설정으로 청킹한 결과를 실시간으로 미리볼 수 있습니다. 실제 인덱싱 전에 청크 크기와 분할 품질을 확인하세요.
인덱싱 옵션 (Step 3)
인덱싱 옵션은 청크가 저장소에 저장되는 방식과 검색 모드를 설정합니다.
| 옵션 | 설명 | 기본값 |
|---|---|---|
| 검색 모드 | 인덱싱에 사용할 검색 방식 | 하이브리드 (HYBRID) |
검색 모드
| 모드 | 설명 |
|---|---|
| 시맨틱 전용 (Semantic Only) | 벡터 DB에만 저장, 의미 기반 유사도 검색 |
| 키워드 전용 (Keyword Only) | 텍스트 검색 DB에만 저장, BM25 키워드 검색 |
| 하이브리드 (권장) | Vector + Text 동시 저장, 두 검색 방식을 결합 |
검색 모드는 Knowledge의 저장소 타겟(Settings에서 설정)과 연동됩니다. 예를 들어 Knowledge에 Vector DB만 활성화된 경우, Keyword Only 모드를 선택해도 Text DB에 저장되지 않습니다.
업로드 후 상태 모니터링
파일을 제출하면 문서는 자동으로 처리 파이프라인을 거칩니다. 문서 목록에서 각 문서의 현재 상태를 확인할 수 있습니다.
문서 상태
| 상태 | 색상 | 설명 |
|---|---|---|
| 대기 중 (Pending) | 파랑 | 처리 대기 |
| 준비 중 (Ready) | 파랑 | 준비 중 |
| 처리 중 (Processing) | 파랑 (애니메이션) | 파싱/청킹/인덱싱 진행 중 |
| 완료 (Completed) | 초록 | 인덱싱 완료 |
| 일시 정지 (Paused) | 노랑 | 일시 정지됨 |
| 실패 (Failed) | 빨강 | 처리 실패 |
| 취소됨 (Cancelled) | 회색 | 사용자에 의해 취소됨 |
| 재인덱싱 중 (Reindexing) | 파랑 (애니메이션) | 재인덱싱 진행 중 |
진행 중인 상태(대기 중·준비 중·처리 중·재인덱싱 중)의 문서는 5초 간격으로 자동 폴링하여 최신 상태를 갱신합니다.
상태별 액션
- 처리 중 (Processing): 중지(Stop) 가능
- 일시 정지 (Paused): 재개(Resume) 또는 취소(Cancel) 가능
- 완료 (Completed): 재인덱싱(Reindex) 가능
- 실패 (Failed): 에러 메시지 확인 후 재시도 가능
문서 상세 페이지
업로드가 완료된 문서를 클릭하면 /knowledge/:knowledgeId/documents/files/:docId 경로의 상세 페이지로 이동합니다. 이 페이지에서 다음을 확인할 수 있습니다:
- 인덱싱 상태 카드: 현재 처리 상태와 진행 정보
- 청크 목록: 생성된 청크를 페이지 단위로 조회
- 파일 다운로드: 원본 파일 다운로드
- 재인덱싱: 옵션을 변경하여 다시 인덱싱
정밀 모드(정확 (ACCURATE) 테이블 모드 + OCR 활성화)는 처리 시간이 길지만 복잡한 레이아웃의 PDF에서 더 정확한 결과를 얻을 수 있습니다. 간단한 텍스트 문서는 기본 설정으로 충분합니다.
페이지가 많거나 레이아웃이 복잡한 파일을 처리할 때는 document_timeout 값을 기본값(90초)보다 높게 설정하는 것을 권장합니다. 타임아웃 초과 시 파싱이 실패할 수 있습니다.